Rückkopplungsschleifen, Modellvalidierung und Neuschulung: Die Genauigkeit von sensXPERT



sensXPERT Digital Mold ist eine Prozesssteuerungslösung, die Hersteller befähigt, ihre Kunststoffherstellungsprozesse zu optimieren und zu digitalisieren. Vorhersagende maschinelle Lernmodelle sind zentral für diese Technologie, da sie den genauen Zeitpunkt bestimmen, an dem verarbeitete Materialien einen bestimmten Aushärte- oder Kristallisationsgrad erreicht haben werden. Daher hängt Digital Mold stark von der Genauigkeit und Effektivität der von ihm verwendeten Modelle ab.
Wie stellt sensXPERT sicher, dass unsere Modelle Zuverlässigkeit und Präzision beibehalten, und wie können Kunden sicher sein, dass ihr neu prognostizierender Prozess Produkte von herausragender Qualität generieren wird? Die Antwort liegt in einer Kombination von Feedback-Schleifen, Modellvalidierung und Neuschulung.
In diesem Artikel erklären wir, wie Modelle trainiert und validiert werden, erörtern die Bedeutung von Modellvalidierung und Neuschulung und werfen einen Blick auf die vorhersagende Analyse in der Fertigung. Anschließend klären wir, wie das sensXPERT-Team die Genauigkeit der maschinellen Lernmodelle des Digital Mold gewährleistet.
Training und Validierung von Machine Learning-Modellen
In einem Artikel über künstliche Intelligenz und maschinelles Lernen definierten wir maschinelles Lernen als „eine Teilmenge von KI, die es Maschinen ermöglicht, aus Daten zu lernen“. Modelle des maschinellen Lernens zielen darauf ab, ein Problem zu lösen, indem sie Muster und Trends in bestimmten Datensätzen analysieren. Diese Muster werden anschließend verwendet, um Entscheidungen oder Vorhersagen zu generieren.
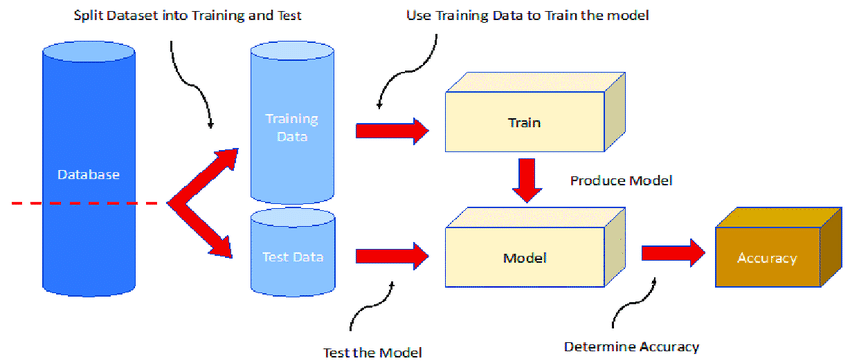
Der gesamte Prozess des maschinellen Lernens beginnt mit einem Datensatz. Um Voreingenommenheiten im Entscheidungsprozess des resultierenden Modells zu vermeiden, ist es unerlässlich, den Datensatz zu teilen. Das Teilen des Datensatzes ist der Prozess, einen Datensatz in zwei oder mehr Teilmengen für das Training, das Testen und möglicherweise die Validierung des Modells aufzuteilen.
Das Teilen des Datensatzes gewährleistet die Zuverlässigkeit des Modells, seine Fähigkeit zur Verallgemeinerung auf neue Daten und seine Wirksamkeit in realen Szenarien. Es gibt verschiedene Arten von Datenaufteilungen, wie zum Beispiel die Trainings-Test-Aufteilung, bei der die Testdaten während des Trainings zurückgehalten werden.
Quelle: https://www.researchgate.net/figure/Training-and-validation-scheme-for-machine-learning-methods-The-database-is-split-and_fig1_357570421
Das Trainingset wird verwendet, um das maschinelle Lernmodell zu trainieren, und das Testset wird verwendet, um seine Leistung zu validieren. Typische Aufteilungsverhältnisse sind 70:30 und 80:20, sodass der Großteil des Datensatzes für das Training des Modells verwendet wird.
Die Bedeutung von Modellvalidierung und Neuschulung
Nachdem die maschinellen Lernmodelle trainiert wurden, wird das resultierende Modell gegen ein Testdatenset validiert, um seine Leistung auf neuen, nicht gesehenen Daten zu bewerten und sicherzustellen, dass es für den Einsatz in realen Szenarien vorbereitet ist. Die Validierung des Modells ist ein wichtiger Schritt im Entwicklungsprozess, da sie die Genauigkeit der Modellausgaben gewährleistet.
Wenn mehrere Modelle entwickelt werden müssen, erfolgt das Training am Testsatz, und das ausgewählte Modell ist dasjenige, das die beste Leistung erbringt. In diesem Fall ist ein dritter Datensatz erforderlich, um das Modell an nicht gesehenen Daten zu validieren.
Nachdem ein Modell implementiert wurde, ist die Neuschulung ein entscheidender Schritt, um die Genauigkeit eines Modells zu stärken. Das Neuschulen des maschinellen Lernens ist der Prozess, bei dem das trainierte Modell mithilfe neuer Daten aktualisiert und verbessert wird. Häufiges Neuschulen führt zur fortgesetzten Relevanz, Genauigkeit und Anpassungsfähigkeit eines Modells an sich ändernde Umstände wie Datenverschiebungen oder Parameteränderungen.
Wie werden die maschinellen Lernmodelle von sensXPERT in einer Kunststoffproduktionsumgebung verwendet und verfeinert?
Prädiktive Analytik in der Kunststoffherstellung
Wie zu Beginn erwähnt, verwendet sensXPERT maschinelle Lernmodelle, um den Zeitpunkt vorherzusagen, an dem ein Teil im Produktionszyklus der Kunststoffherstellung den gewünschten Aushärtegrad oder die gewünschte Kristallisation des Herstellers erreicht haben wird.
Verschiedene Hindernisse können den Kunststoffherstellungsprozess beeinträchtigen, darunter Qualitätsschwankungen, Materialabweichungen, mangelnde Transparenz und infolgedessen Mängel an Endprodukten. Daher gewinnen predictive Analytics erheblich an Bedeutung. Technologien und Innovationen, die potenzielle Systemausfälle vorhersagen, Produktionspläne optimieren und den Lagerbestand prognostizieren, wurden entwickelt, um die Kunststoffproduktion zu optimieren und unnötige Stillstandszeiten zu vermeiden.
Quelle: What is Predictive Analytics? | Qualtrics
sensXPERT verwendet predictive Analytics, um direkt in Spritzgussmaschinen zu schauen und die Ergebnisse laufender Produktionszyklen vorherzusagen, um eine dynamische Prozesskontrolle zu ermöglichen. Der sensXPERT Digital Mold ermöglicht es Herstellern, Qualitätskontrollen an jedem produzierten Teil durchzuführen, ihre Sicherheitspuffer zu entfernen, Zykluszeiten zu reduzieren, von weniger Ausschuss zu profitieren und insgesamt die Kosteneffizienz zu steigern.
Im Zentrum dieser Lösung stehen die maschinellen Lernmodelle von sensXPERT. Die Modelle werden auf Grundlage von Prozessdatensätzen erstellt – wie in den vorherigen Abschnitten erläutert – und starken Feedback-Schleifen. Zum Beispiel wird ein Kunde dem datenwissenschaftlichen Team von sensXPERT mehrere Sätze von Prozessdaten zur Verfügung stellen. Der Kunde wird auch klären, welche Zyklen akzeptabel waren und welche Zyklen problematisch waren, zusammen mit spezifischeren Prozessinformationen. Problematische Zyklen können Verunreinigungen, kurzzeitige Füllungen, Verzug, Alterung oder andere ähnlich suboptimale Merkmale aufweisen.
Mit diesem Feedback kann das Team von sensXPERT ein Modell angemessen mit der oben beschriebenen Holdout-Methode trainieren. Nachdem das Modell trainiert und implementiert wurde, führt das Team von sensXPERT systematische Validierungsexperimente am Modell durch, um dessen fortgesetzte Genauigkeit zu gewährleisten.
Verlässliche Rückkopplungsschleifen
Feedback-Schleifen sind entscheidend für die Aufrechterhaltung der maschinellen Lernmodelle von sensXPERT. Wenn ein Kunde beispielsweise seine Prozessparameter ändert, ermöglicht die zeitnahe Rückmeldung an sensXPERT dem Team, das Modell zu validieren und sicherzustellen, dass es genau darstellt, wie bestimmte Änderungen und Schwankungen die Prozessergebnisse beeinflussen. Daher kann das Modell effektiv zur erfolgreichen Prozesskontrolle und -optimierung beitragen.
In ‚Vorstellung: Der sensXPERT-Weg der KI‘ beschreiben wir, wie wir maschinelle Lernmodelle verwenden, um die Optimierung von Polymerprozessen zu ermöglichen. Zusammengefasst hostet das sensXPERT Edge-Gerät maschinelle Lernmodelle und setzt sie auf Echtzeitdaten ein, die von den in-mold Materialcharakterisierungssensoren von sensXPERT gesammelt wurden, um eine Vorhersage über den optimalsten Zeitpunkt für das Beenden eines Zyklus zu generieren.
